ECCV 2016 Hydra CCNN
Towards perspective-free object counting with deep learning,这是一篇发在ECCV 2016上的论文,提出一种多输入的CNN模型来解决Object Counting的问题。
Object Counting
定义
给定一张图片,输出图片中目标对象的个数,比如下面两张图,左图有36个车,右图有8个猪

常用方法
Counting by detection
用检测器去检测图中有多少个对象,检测到多少个就认为是多少个

检测有三种方法,整体的检测(图a,检测整个人),部分的检测(图b,检测头),形状的匹配(图c,人的形状抽象成几何图形)
- Counting by Clustering

- 在摄像头捕捉到的连续视频帧里,目标移动时,在多个帧之间的位置比较相近,将这些运动物体在多帧图片之间做聚类,聚类中心的个数就是目标的个数
- 不适用于静止物体
- 优点:无监督
更多细节可看Related work部分的参考文献
- Counting by Regression
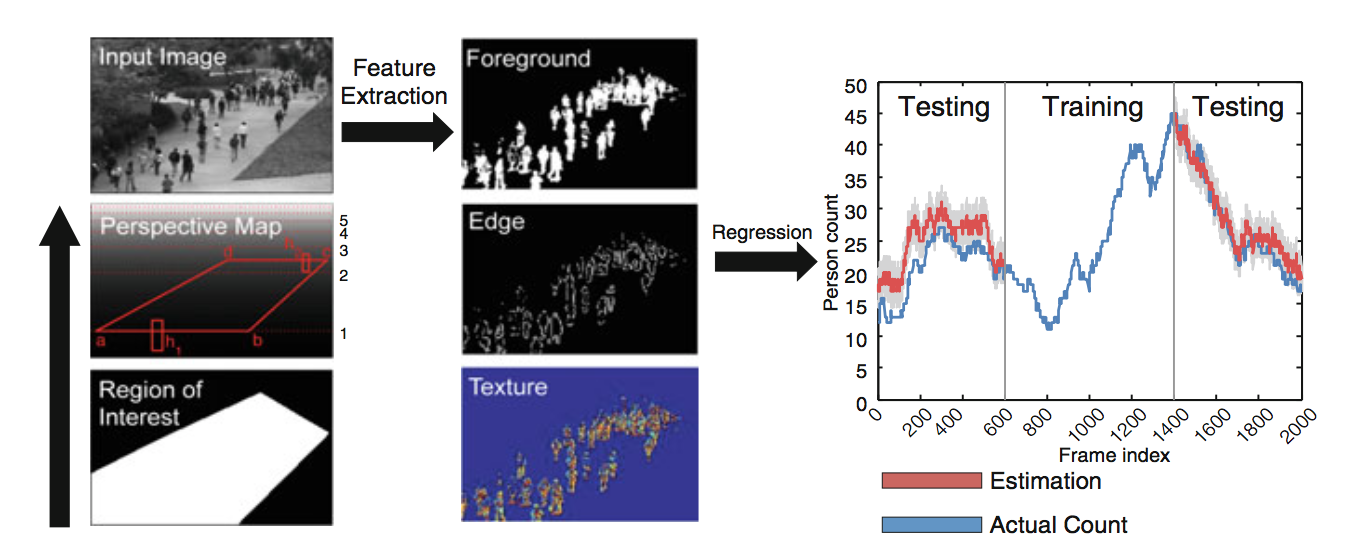
- 给定输入图片,ROI,透视图(场景中由远及近的几何关系,用于缩放对象)
- 提取特征(背景分离,边缘检测,纹理识别)
- 学习一种映射,将特征回归到对象数量上
回归又分两种,
- 回归对象数量
- 回归对象密度图
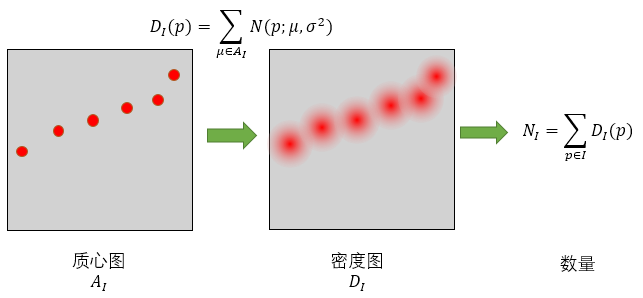
具体讲一下对象密度图:
- 先给出原图和目标对象的坐标(可以根据坐标画出质心图)

- 对质心图做一个高斯滤波,可以得到密度图,作为回归的目标,对质心图进行求和,反过来可以得到目标的数量
进入正题,Hydra CCNN
- 方法: 回归密度图,多尺度输入组合
- 优势:不需要透视图,多尺度鲁棒性,训练简单,误差小
CCNN(Counting CNN)
Regression: 用一个CNN将原始图像映射为对象密度图
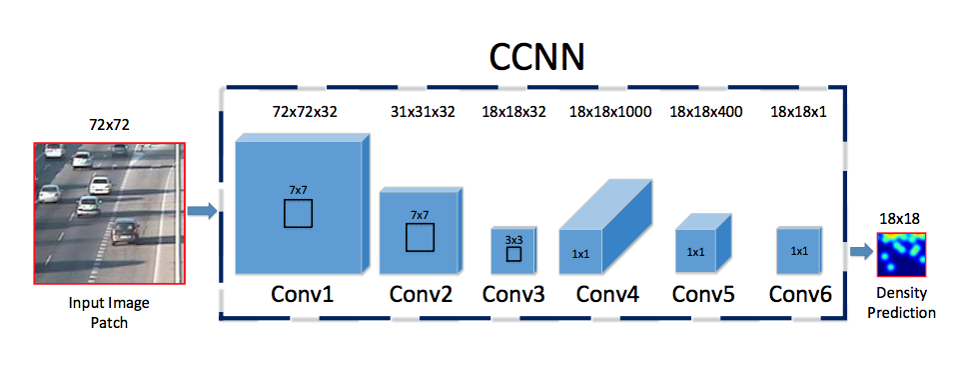
其中P是image patch,是CNN参数
- Conv1, Conv2, Conv3后面都跟着一个max pooling层
- Conv4和Conv5都是卷积层(比全连接层更快,参数更少)
- 对比论文中提到的另一种方法:Zhang et al:卷积后接全连接层,损失为密度图和数量的回归误差,两个损失交替进行优化,CCNN更快,并且训练更简单。
- Loss: ,gt是ground truth的意思,这个损失就是求每张图的密度图的预测插值的l2模,然后求平均,N为图片数量
- 训练:滑动窗口将图片划分为多个网格,对每个网格做回归,将回归的密度图拼接成一个完整尺寸的密度图
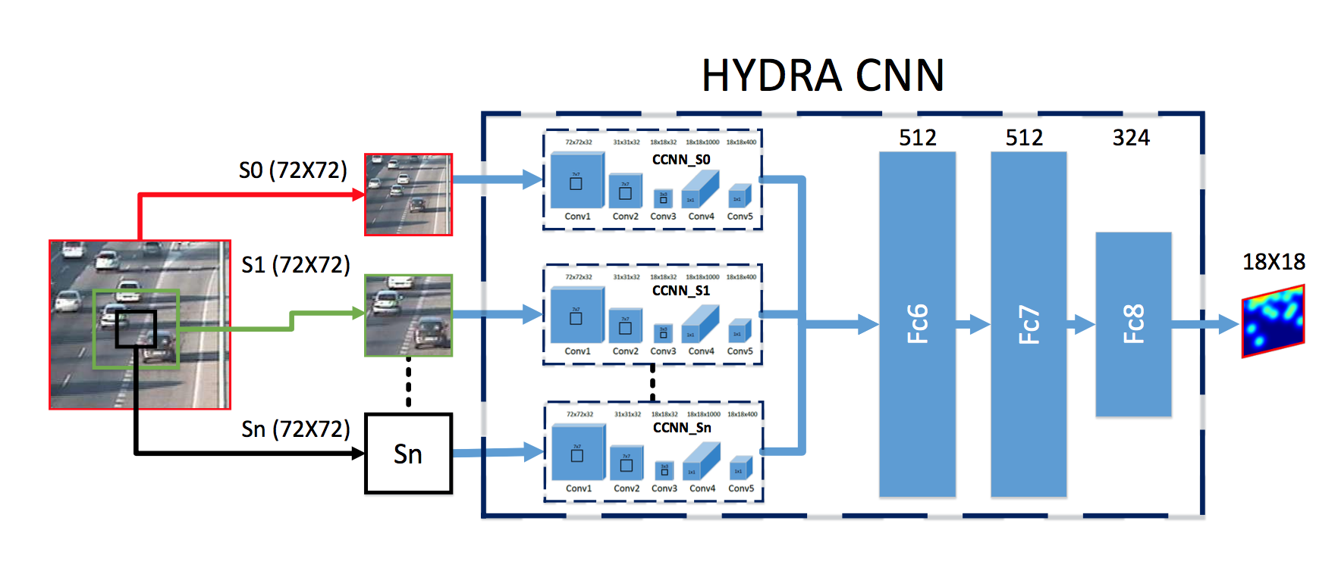
Hydra CCNN
Hydra: 海德拉是希腊神话中的九头蛇
- Motivation: 多尺度范围内的对象大小不同,会导致计数出错
- Solution: 用多个CCNN各自回归多个尺度的密度图,组合成最终密度图
举个例子:n=3时,也就是回归三个尺度的密度图,
- S0: 整个patch(不是整张图,是一个patch,前面讲了会做滑窗划分)
- S1:在中间抠出面积为2/3的图
- S2:在中间抠出面积为1/3的图
私以为这个地方还有改进空间
实验结果
数据集
- TRANCOS(汽车),UCSD(行人),UCF_CC_50(行人)
- 评价指标:
- MAE(Mean Absolute Error)
- GAME(Grid Average Mean Absolute Error):GAME(L) = \frac{1}{N}\sum{n=1}^{N}\sum{l=1}^{4^L}|D{I_n}^{l}-D{I_n^{gt}}^{l}|
- N是图片总数
- L: 对于每张图,划分成个小格,计算每个小格的误差
- L为0时就是MAE