分类网络最新进展
Self-training with Noisy Student improves ImageNet classification
CVPR2020
Method
- 在有标签数据上训练Teacher,在无标签数据上预测伪标签
- 用有标签数据和伪标签数据从头训练一个Student模型,Student模型
- 把Student当成Teacher,迭代,效果最好的是迭代三次
特别的地方在于:
- model noise: Student比Teacher大,多了Dropout和stochastic depth(训练时,重复的block中,某些会被设置成identity)
- data noise:训练数据加Data augumentation()
- 一些trick:
- Teacher网络置信度低的,不会用于训练;
- ImageNet每个类的图像数量差不多,因此带伪标签的unlabel data也在类别上做了平衡,数量多的类只保存一部分,数量少的类多复制几份
效果
感觉其实这些操作平平无奇,效果比有监督的EfficientNet-L2(480M,85.5%)提升了一点:(480M,88.7%)
Meta Pseudo Labels
Motivation
使用伪标签无监督学习的方法,因为伪标签可能是错的,所以Student不能超越Teacher,如果能让Teacher在过程中也得到训练,输出更好的标签,Student就有希望输出更好的结果。
Method
- 在有标签数据上先训练一个Teacher,在无标签数据上预测伪标签
- 用伪标签数据训练Student
- Student在有标签数据上测试,得到Loss
- Teacher根据Student在有标签数据上的Loss,对自身权重进行修正(关键就在于如何修正)
Detail
假如用伪标签方案训练Student,那么训练目标可以这样表示:
其中,
如果根据Student在有标签数据集上的表现,优化Teacher,那这个目标可以表示为:
其中,就是伪标签方案下,在Teacher网络的参数下,优化出的最优Student参数,即
所以问题就在于如何解这个优化问题:,
首先可以通过梯度下降法迭代得到,但它是一个多步的优化过程才能得到的结果,我们用单步优化的结果来近似:,那么优化目标就变成了:;
那么每在伪标签数据上更新一次Student,就可以在有标签数据上算出Teacher的权重更新量,对Teacher进行更新:,其中两个梯度都是对CE求导,因此这个更新量可以很容易地求出来;
辅助Loss
单独用上面的方法已经可以得到不错的结果了,但如果在训练的时候,配合其他Loss训练,效果更佳;文中提及了unsupervised domain adaption的一些方法,可以在论文附录查询到。
效果
在ImageNet上首次干到了90.2%的top1 ACC
EfficientNet: Rethinking model scaling for convolutional neural networks
Motivation
这篇论文我更愿意称其为实验报告,研究了如何扩展网络的input resolution, width(channel数), depth(layer数),才能得到性价比最高的网络
Observation
这篇文章基于两个observation来调整网络规模:
- 增加输入/宽度/深度,都能提高模型效果,但存在边际效应,加的太多提升不明显;
- 因此,与其把多出来的算力堆在单个维度上,不如同时扩张三个维度;
Method
具体的扩张策略如下:
- 假设depth变成倍,那么FLOPS会变为倍,假设width(卷积的输入和输出通道数)变为倍,那么FLOPS会变为倍,假设输入宽度变为,那么FLOPS变为;
- 我们希望调整参数后,FLOPS变为,那么就要求,因此具体的调整策略就变成了:
- depth:
- width:
- resolution:
- st: ,
Network
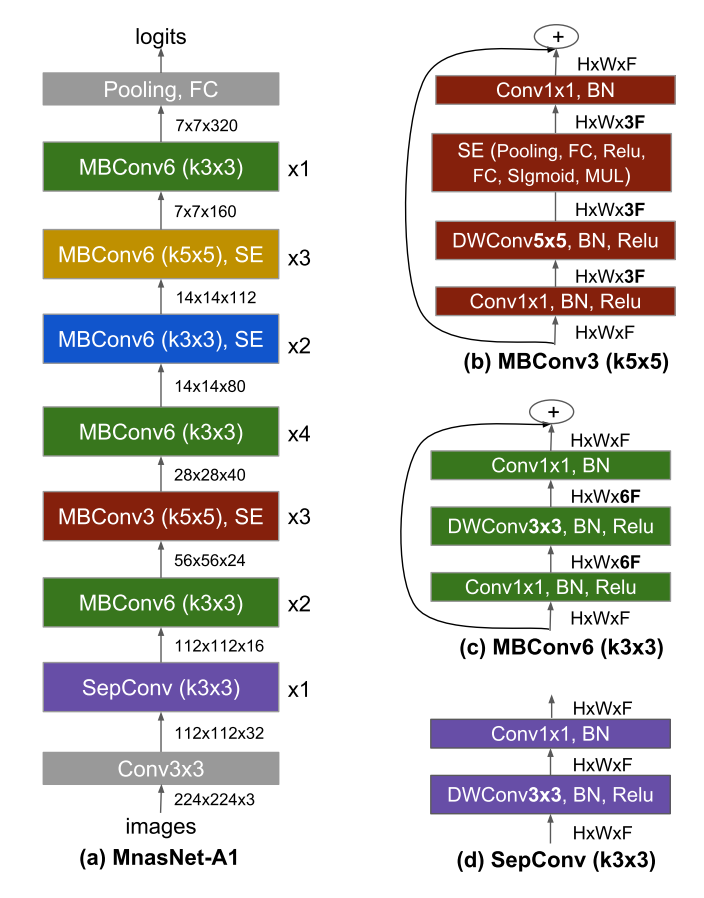
在各种基础网络上试了这个策略,发现Mnas上改出来的最好,网络结构大概长这样,但是size会有所不同,比如EfficientNet-B0就是
Result
MLP-Mixer: An all-MLP Architecture for Vision
使用MLP代替卷积,保留skip connection和normalization,在ImageNet上最高达到87.94%
Method
- 将图像分成S个PxP大小的patch,每个patch(n c p p) reshape成(n c p*p)的tensor
- 用一个矩阵乘法先将每个patch处理一下reproject到n C,所有 patch合起来就是n S * C的tensor X
- 接下来开始mlp:
- 对X做layer norm
- 先对每个patch做乘法,,变成
- 做一个非线性变换,这里用的是GELU
- 再做一个乘法,从变成
- 再做一个残差加上X
- 这里不同channel之间的权重是共享的,用来减少参数数量
- 由于中间token数量变了,patch数目没变,起一个花里胡哨的名字,把patch叫做token,乘法叫做token-mixing,也就是将同个通道不同token先混合一下
- 再做一个MLP:
- 也是一样的操作,不同之处在于中间是channel数量变了,后面又变回来,所以叫channel-mixing
- 每个mlp-mixer block都做四次乘法,把的tensor变成
- 网络最后接一个Global Average Pooling做分类
- 训练的时候也是一样预训练+finetune
MLP-Mixer的卷积本质
- 一开始分不同patch,其实就是一个,stride为的卷积
- 不同位置相同通道的混合,可以用深度可分离卷积代替 ·- 同个位置不同通道的混合,可以用一个1x1的卷积代替