读论文系列·Fast RCNN
Fast RCNN是对RCNN的性能优化版本,在VGG16上,Fast R-CNN训练速度是RCNN的9倍, 测试速度是RCNN213倍;训练速度是SPP-net的3倍,测试速度是SPP-net的3倍,并且达到了更高的准确率,本文为您解读Fast RCNN。
Overview
Fast rcnn直接从单张图的feature map中提取RoI对应的feature map,用卷积神经网络做分类,做bounding box regressor,不需要额外磁盘空间,避免重复计算,速度更快,准确率也更高。
Related work
RCNN缺点
- Multi-stage training
需要先预训练卷积层,然后做region proposal, 然后用SVM对卷积层抽取的特征做分类,最后训练bounding-box回归器。
- 训练时间和空间代价很大 训练过程中需要把CNN提取的特征写到磁盘,占用百G级的磁盘空间,GPU训练时间为2.5GPU*天(用的是K40,壕,友乎?)
- 目标检测很慢 Region proposal很慢,VGG16每张图需要花47秒的时间
总结:RCNN就是慢!最主要的原因在于不同的Region Proposal有着大量的重复区域,导致大量的feature map重复计算。
SPP-net
SPP-net中则提出只过一遍图,从最后的feature map裁剪出需要的特征,然后由Spatial pyramid pooling层将其转为固定尺寸特征,由于没有重复计算feature map,训练速度提升3倍,测试速度提升了10-100倍。
但是SPP-net也有缺点,SPP-net的fine-tune不能越过SPP层,因为pyramid BP开销太大了,只能fine-tune全连接层,tune不到卷积层,所以在一些较深的网络上准确率上不去。
Fast RCNN architecture
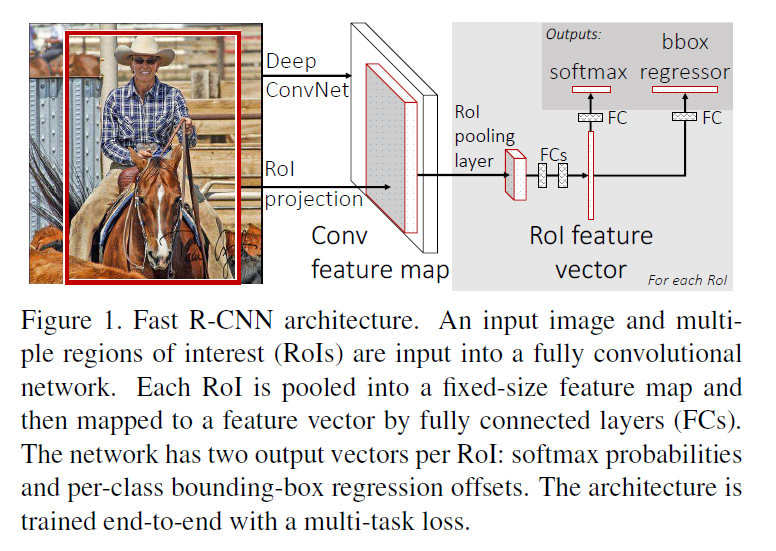
- 首先将整个图片输入到一个基础卷积网络,经过max pooling得到整张图的feature map,
- 然后用一个RoI pooling层为region proposal从feature map中提取一个固定长度的特征向量,
- 每个特征会输入到一系列全连接层,得到一个RoI特征向量,
- 再分叉传入两个全连接层输出,
- 其中一个是传统softmax层进行分类,
- 另一个是bounding box regressor,
- 根据RoI特征向量(其中包含了原图中的空间信息)和原来的Region Proposal位置回归真实的bounding box位置(如RCNN做的那样,但是是用神经网络来实现)。
其他都是一目了然的,接下来主要讲RoI pooling
RoI pooling
我们可以根据卷积运算的规则,推算出原图的region对应feature map中的哪一部分。但是因为原图region的大小不一,这些region对应的feature map尺寸是不固定的,RoI pooling就是为了得到固定大小的feature map。
- RoI pooling层使用max pooling将不同的RoI对应的feature map转为固定大小的feature map。
- 首先将h w的feature map划分为H W个格子
- 对每个格子中的元素做max pooling
由于多个RoI会有重复区域,所以max pooling时,feature map里同一个值可能对应pooling output的多个值。所以BP算梯度的时候,从RoI pooling层output y到input x的梯度是这样求的
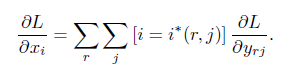 其中
其中
- ,也就是在这个区域中做max pooling得到的结果,
- 是一个条件表达式,就是判断input的是否是max pooling的结果,如果不是,输出的梯度就不传到这个值上面
- r是RoI数量,j是在一个region中,与x对应的输出个数
- 是第j个跟x对应的输出
举例:
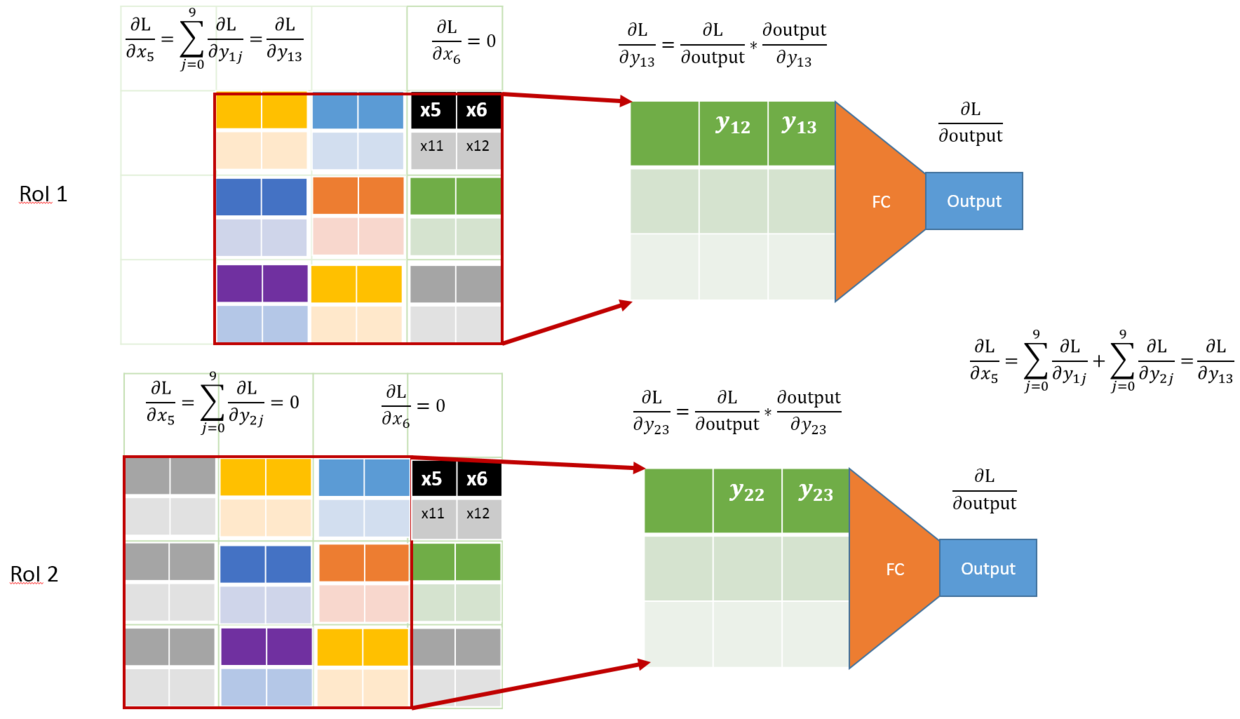
也就是说,将Loss对输出的梯度,传回到max pooling对应的那个feature unit上,再往回传
其实这是SPPnet的一个特例,是Spatial pooling,没有pyramid,也因此计算量大大减少,能够实现FC到CNN的梯度反向传播,并且,实验发现其实feature pyramid对准确率提升不大。倒是原图层面的Pyramid作用大些:
- 训练时,为每张训练图片随机选一个尺度,缩放后扔进网络学
- 测试时,用image pyramid为每张测试图片中的region proposal做尺度归一化(将它们缩放到224x224)
但是这种Pyramid方法计算代价比较大,所以Fast RCNN中只在小模型上有这样做
Multi-task loss
- : SoftMax多分类Loss,没啥好说的
- :bounding box regression loss
定义真实的bounding box为(),预测的bounding box位置(由第二个fc层输出,有K个类,每个类分别有4个值,分别为)
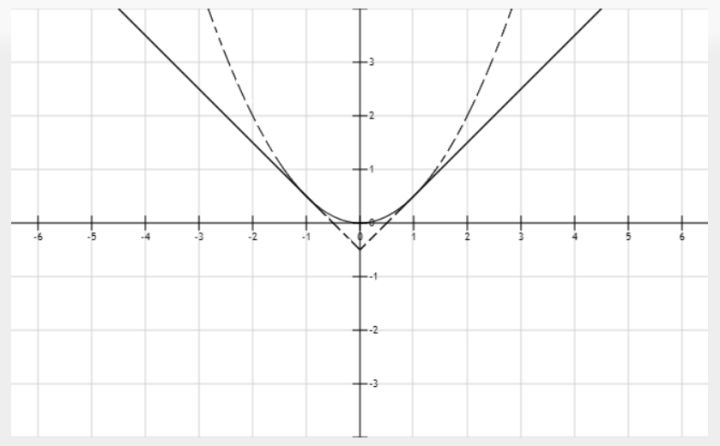
即预测位置和真实位置四个值的差值求和,其中
是一个软化的L1(画一下图像可以看出来,在(-1,1)的范围内是抛物线,没L1那么尖锐),如果采用L2 loss,需要仔细调节学习率防止梯度爆炸。
 整个模型的Loss就是:
整个模型的Loss就是:
- p代表预测类别,k代表真实类别
- k≥1意味着不算0类(也就是背景类)的bounding box loss,因为背景的bounding box没啥意义
- λ是超参数,在论文的实验中设为1
训练
- ImageNet预训练
- 最后一层换成RoI pooling层
- FC+sofmax分类层换成两个FC,分别求softmax分类和bounding box回归loss,每个类有自己的bounding box regressor
- 用Detection数据BP微调整个神经网络
这就比较厉害了,谁不喜欢end to end,之前RCNN是需要分开微调SVM分类层和bounding box regressor的
前面讲了RoI pooling使得梯度反向传播到卷积层成为可能,但是这种BP训练仍然很耗显存和时间,尤其是在输入的ROI属于不同图片时,因为单张图的feature map是不存到磁盘的,当一张图的几个RoI和其他图的几个RoI混在一起交替输入时,需要反复前向传播计算feature map,再pooling,实际上也就反复计算了feature map。
在Fast RCNN的训练中,每次输入两张图(这么小的batch size),每张图取64个ROI,单张图的多个ROI在前向计算和后向传播过程中是共享feature map的的,这样就加快了训练速度。
然而,这犯了训练中的一个忌讳,实际上,相当于训练数据(ROI)没有充分shuffle,但在Fast RCNN的实验中效果还行,就先这样搞了。
样本筛选
- 正样本:与bounding box有超过50%重叠率的
- 负样本(背景):与bounding box重叠率位于0.1到0.5之间的。
Truncated SVD加速全连接层运算
- Truncated SVD
将大小的矩阵W分解为三个矩阵相乘,其中,是一个的矩阵,包含的前个左奇异向量,是一个的对角矩阵,包含的前个上奇异向量,是一个的矩阵,包含的前个右奇异向量,参数数量从变成,当远小于时,参数数量就显著少于。
具体实现上,将一个权重为W的全连接层拆成两个,第一层的权重矩阵为∑_{t}V^{T}(并且没有bias),第二层的权重矩阵为U(带上W原来的bias)。
在Fast RCNN中,Truncated SVD减少了30%的训练时间。
实验结果
PK现有方法
- 在VOC12上取得65.7%的mAP,是当时的SOA
- 在VGG16上,Fast R-CNN训练速度是RCNN的9倍, 测试速度是RCNN213倍;
- 训练速度是SPP-net的3倍,测试速度是SPP-net的3倍
创新点必要性验证
- RoI pooling是否比SPP更优?(是否有fine tune卷积层的必要?)
- 使用VGG16,在Fast RCNN中冻结卷积层,只fine tune全连接层:61.4%
- 使用VGG16,在Fast RCNN中fine tune整个网络:66.9%
- Multi Loss(Softmax + bb regressor)是否比Single task(只用Softmax loss)更优?stage-wise和Multi Task同时进行(end2end)哪个更优?
在VOC07上,end2end + bb regressor > stage-wise+ bb regressor > end2end
- Image Pyramid是否必须? 实际上,使用Pyramid在Fast RCNN上只提升了1%左右,所以这个也没被列为正式的创新点
- 如果用SVM来分类会不会更好?
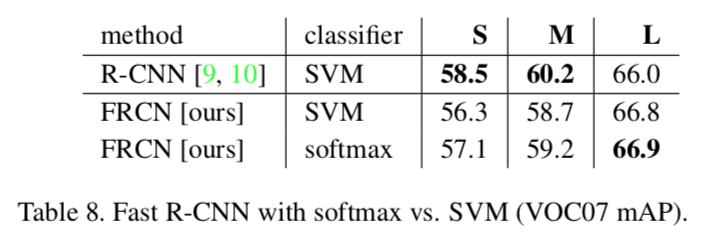 S M L是由浅到深的三个网络,可以看到,只用Softmax分类也能达到不错的效果,在网络比较深的情况下,也有超越SVM的可能。
S M L是由浅到深的三个网络,可以看到,只用Softmax分类也能达到不错的效果,在网络比较深的情况下,也有超越SVM的可能。
模型泛化能力
一个模型如果能够在更多训练数据的条件下学到更好的特征分布,这个模型效果越好,RBG用VOC12去训练Fast RCNN,然后在VOC07上测试,准确率从66.9%提升到70.0%。在其他组合上也取得了提升。
注意,在训练更大的数据的时候,需要更多的iteration,更慢的learning rate decay。
- 使用更多的Region Proposal效果会不会更好?(不是很想讲这方面,太玄学)
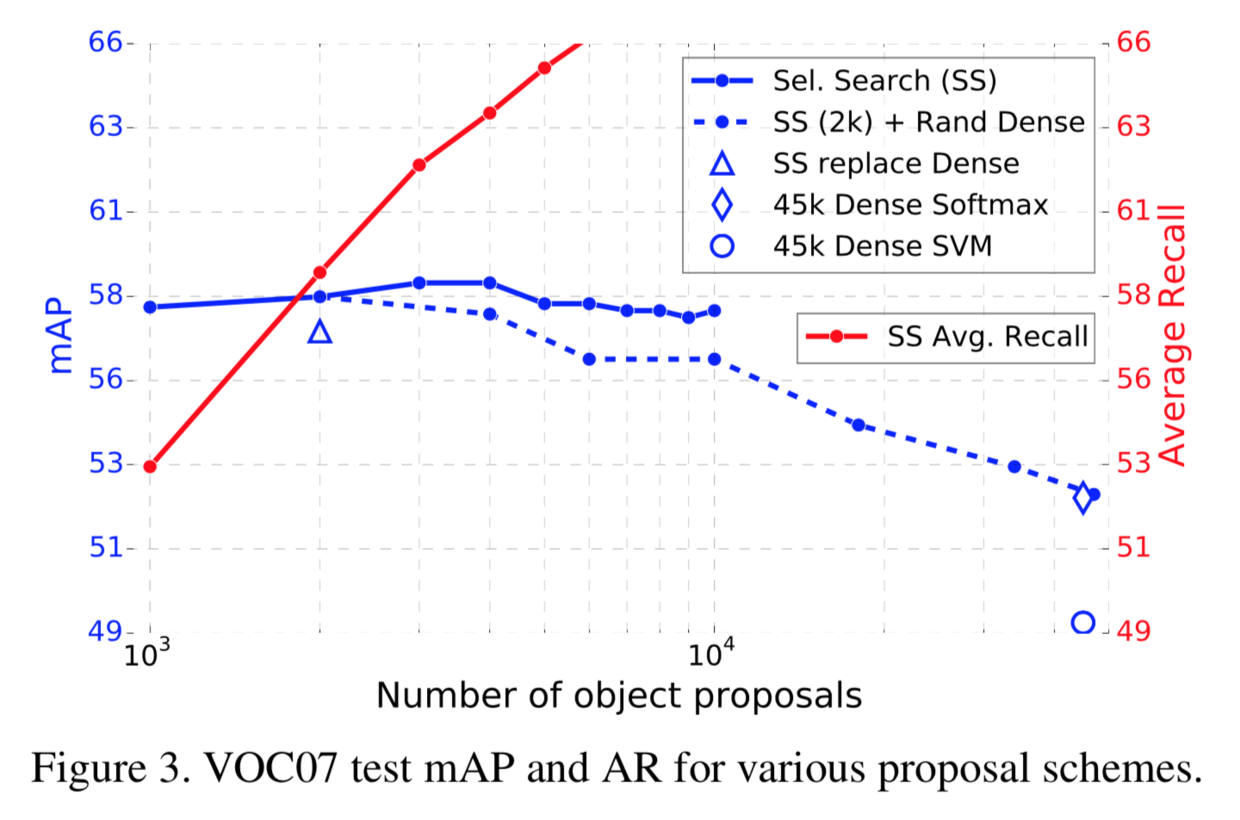 图中红色线表示Average Recall,通常人们用Average Recall来评价Region Proposal的效果,然而,proposals越多,AR这个指标一直往上涨,但实际上的mAP并没有上升,所以使用AR这个指标比较各种方法的时候要小心,控制proposal的数量这个变量不变。
图中红色线表示Average Recall,通常人们用Average Recall来评价Region Proposal的效果,然而,proposals越多,AR这个指标一直往上涨,但实际上的mAP并没有上升,所以使用AR这个指标比较各种方法的时候要小心,控制proposal的数量这个变量不变。
图中蓝色线表示mAP(= AVG(AP for each object class)),可以看到,
- 太多的Region Proposal反而会损害Fast RCNN的准确度
- DPM使用滑动窗口+层次金字塔这种方法提供密集的候选区域,用在Fast RCNN上略有下降。