读论文系列·YOLOv2 & YOLOv3
YOLOv2/YOLO9000
YOLO9000: Better, Faster, Stronger
YOLOv2 是一个单纯的改进型工作,在YOLO上集成了很多已有的trick(比如加了BN,anchor),因为是trick文章,这里就不做完整解读了,可以参考这篇解读,我觉得其中比较有新意的地方有两个:
- Dimension Clusters得到更好的anchor
- YOLO9000:用WordTree整合ImageNet和COCO数据集联合训练Darknet(有种知识图谱和DL结合的感觉),用多个softmax loss分别做不同层次的分类
改进点list:
- Batch Normalization
- 用448x448的图片训练分类器
- 使用anchor
- 聚类得到更好的初始anchor位置(使用IOU进行box距离判断)
- 直接预测box位置
- 类似ResNet的passthrough feature叠加
- 由于是全卷积网络,可以接收不同尺度输入进行训练
- Darknet-19:大量使用3x3和1x1卷积,BN
- 用wordtree整合ImageNet和COCO数据集,多标签联合训练Darknet
YOLOv3
YOLOv3也是一个单纯的改进性工作。。没啥创新性,但是效果好_(:з」∠)_
作者也觉得这不算是一篇正式paper,只是一个工作报告,所以论文写得跟玩儿似的
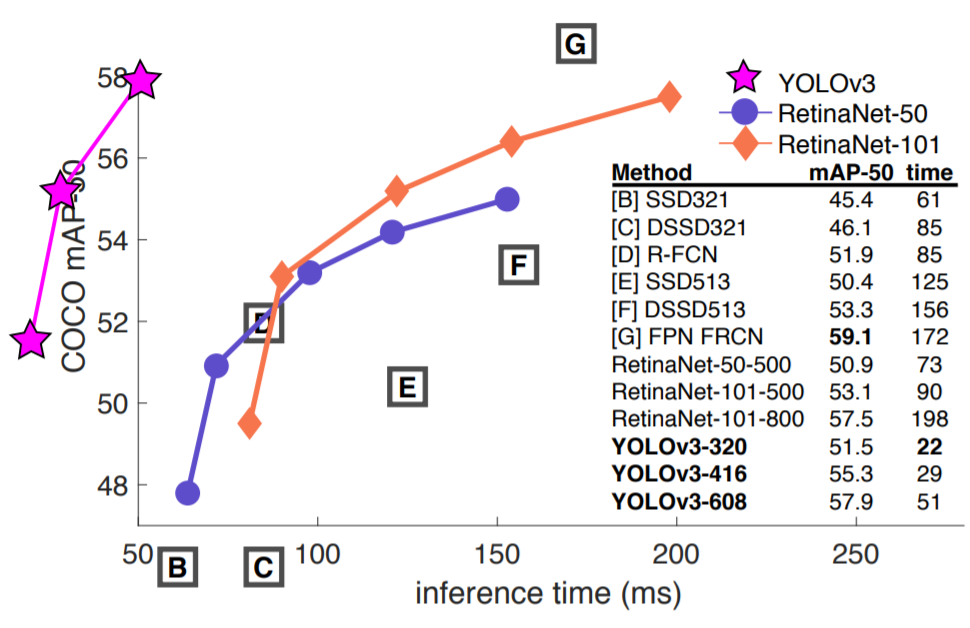 改进点list
改进点list
- 使用更多的shotcut,构造更深的darknet-53(ResNet提出来的)
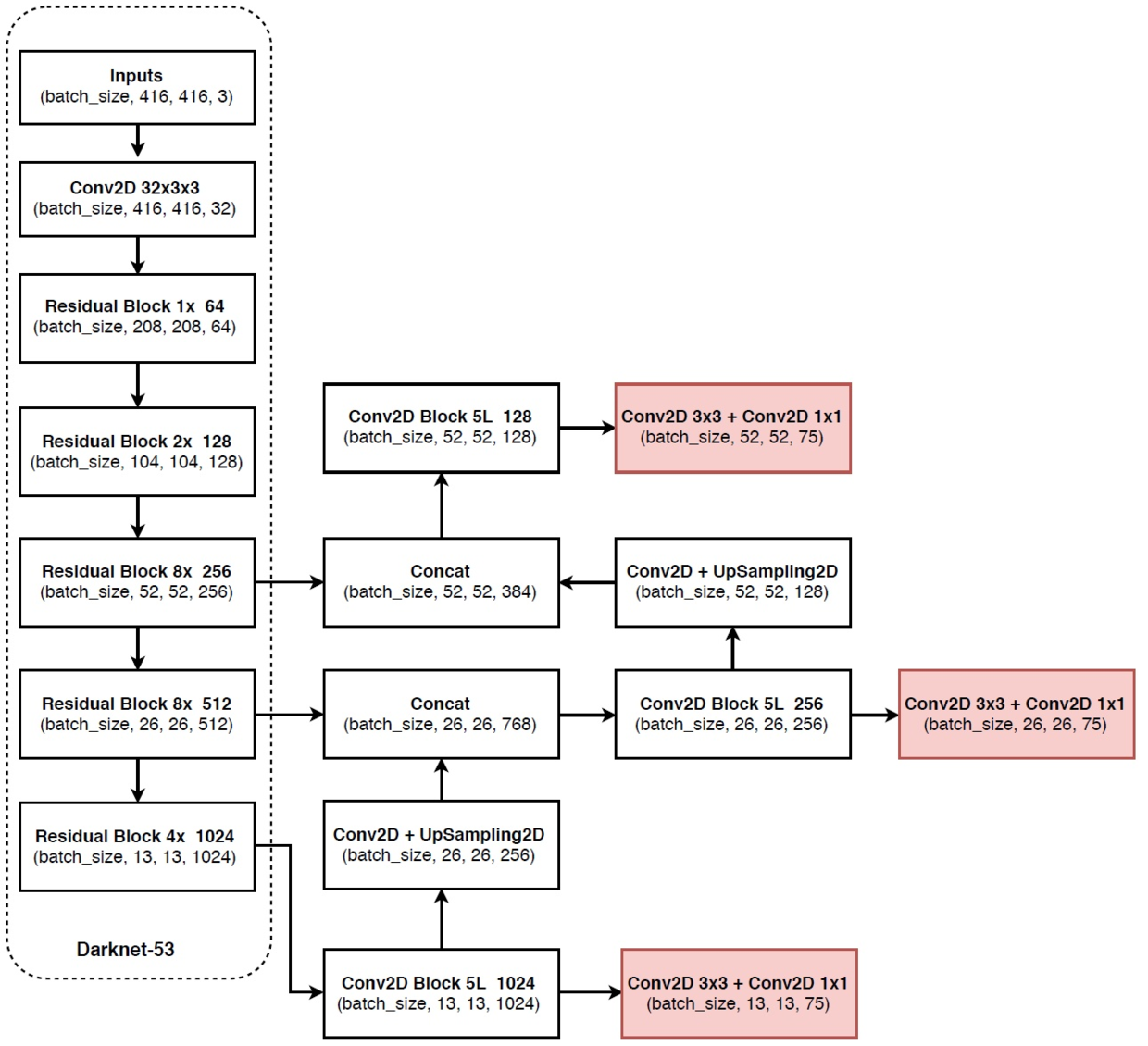
- 使用三层feature map分别对应不同尺度的anchor(SSD,FPN已经这样做过了)
- 由于softmax分类loss前提假设是每个对象只属于一个分类,对于有包含关系的类别,softmax没那么适用,于是yolov3使用了逻辑回归的方法做分类,同时回归一个anchor属于多个类的概率,ground truth值是0或1,分别代表一个anchor是否与ground truth box相匹配。